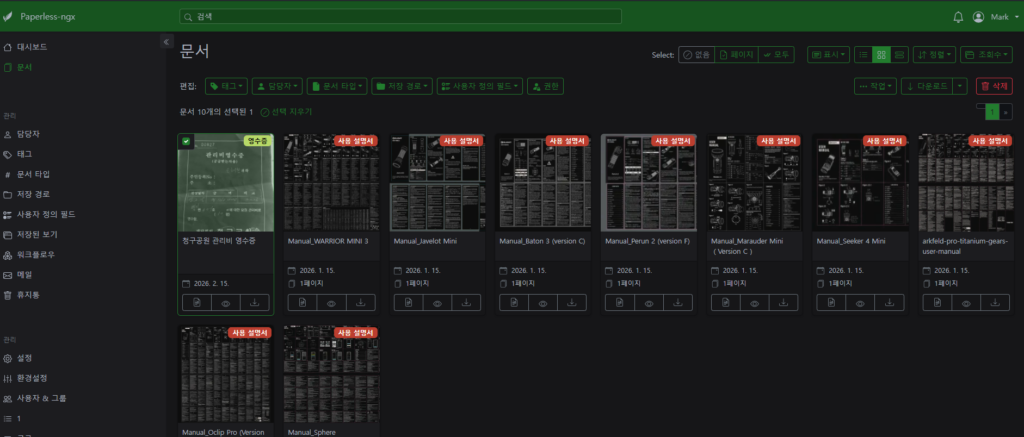
안녕하세요, Mark입니다.
혹시 이런 경험 있으신가요?
“분명히 어딘가에 뒀는데… 작년에 받은 영수증이 어디 갔지?” “병원 진단서 스캔해뒀는데 어느 폴더에 넣었더라?”
서류함은 두껍고, 파일 폴더는 뒤죽박죽이고, 스마트폰 갤러리에는 영수증 사진이 잔뜩 쌓여있고… 종이 문서 관리는 항상 골칫거리입니다.
오늘 소개할 Paperless-ngx는 이 문제를 한 번에 해결해줍니다.
📄 Paperless-ngx가 뭔가요?
Paperless-ngx는 종이 문서와 디지털 문서를 한 곳에서 관리하는 셀프호스팅 문서 관리 시스템입니다.
스캔한 사진이든, PDF든, 영수증 사진이든 집어넣으면 OCR로 텍스트를 인식해서 검색 가능한 디지털 서재로 만들어줍니다.
“Paperless(종이 없는)”라는 이름처럼, 쌓여있는 종이 문서들을 전부 디지털화해서 서랍 속에 처박아두지 않아도 되게 만드는 게 목표예요.
🔍 OCR이 완벽하게 인식되는 건가요?
OCR(광학 문자 인식)의 실제 동작 방식을 설명하면 이렇습니다.
Paperless-ngx는 Tesseract라는 오픈소스 OCR 엔진을 사용합니다. 구글이 개발한 엔진으로 100개 이상의 언어를 지원해요.
잘 되는 경우:
- 깔끔하게 인쇄된 문서
- 선명하게 스캔된 PDF
- 디지털로 생성된 PDF (텍스트 레이어 있는 것)
잘 안 되는 경우:
- 손으로 쓴 글씨
- 흐릿하게 찍힌 사진
- 복잡한 레이아웃의 문서
- 작은 글씨나 특수 폰트
결국 OCR의 역할은 “완벽한 텍스트 추출”이 아니라 “검색에 걸릴 만한 텍스트를 최대한 뽑아내는 것”에 가깝습니다. 영수증 날짜나 금액, 가게 이름 정도가 인식되면 나중에 검색할 때 충분히 찾을 수 있거든요.
✨ 주요 기능
① 문서 자동 처리
문서를 올리면 Paperless가 자동으로 이런 작업을 합니다.
- OCR로 텍스트 추출
- 중복 문서 확인
- 날짜, 발신자(correspondent) 자동 감지
- 태그 자동 제안
② 강력한 검색
OCR로 추출된 텍스트가 전부 검색 인덱스에 올라갑니다. “국민은행”, “2024년 12월”, “건강보험” 같은 키워드로 순식간에 찾을 수 있어요.
③ 머신러닝 자동 분류
문서를 몇 개 올리다 보면 Paperless가 패턴을 학습합니다. 예를 들어 국민은행 명세서를 몇 번 올리면, 다음번엔 “이거 국민은행 문서네요, 금융 태그 달까요?” 하고 자동 제안을 합니다.
④ 지원 파일 형식
| 형식 | 지원 여부 |
|---|---|
| ✅ (텍스트/스캔 모두) | |
| JPG, PNG, TIFF, WEBP | ✅ |
| Word, Excel, PowerPoint | ✅ (Tika 추가 시) |
| 이메일 | ✅ (IMAP 연동 시) |
| 일반 텍스트 | ✅ |
⑤ PDF/A 장기 보관 형식
처리된 문서는 PDF/A 형식으로 저장됩니다. 일반 PDF와 달리 장기 보관을 위해 설계된 국제 표준 형식이에요. 10년 후에도 열 수 있도록 설계된 거죠.
⑥ 이메일 자동 수집
Gmail 등 이메일 계정을 연동하면, 첨부 파일이 있는 이메일을 자동으로 수집해서 Paperless에 저장합니다. 카드 명세서, 통신비 청구서 같은 게 이메일로 오면 자동으로 아카이브되는 거죠.
🤖 AI 연동도 됩니다
최근에는 OpenAI API와 연동하는 Paperless-AI 컨테이너를 추가하는 사람들도 늘어나고 있습니다.
AI가 문서 내용을 분석해서 자동으로 태그를 달고, 긴 문서는 요약까지 해줍니다. Tesseract OCR로 인식한 텍스트를 AI가 한 번 더 분석하는 방식이라 분류 정확도가 훨씬 올라가요.
📦 스택 명령어 (참고용)
Paperless-ngx는 여러 컨테이너가 함께 동작합니다.
version: "3"
services:
paperless-redis:
image: redis:7
restart: always
paperless-db:
image: postgres:16
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: [DB_PASSWORD]
volumes:
- pgdata:/var/lib/postgresql/data
restart: always
paperless:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
depends_on:
- paperless-redis
- paperless-db
ports:
- "8010:8000"
environment:
PAPERLESS_REDIS: redis://paperless-redis:6379
PAPERLESS_DBHOST: paperless-db
PAPERLESS_ADMIN_USER: admin
PAPERLESS_ADMIN_PASSWORD: [ADMIN_PASSWORD]
PAPERLESS_OCR_LANGUAGE: kor+eng
PAPERLESS_TIME_ZONE: Asia/Seoul
PAPERLESS_OCR_LANGUAGES: kor
volumes:
- ./data:/usr/src/paperless/data
- ./media:/usr/src/paperless/media
- ./consume:/usr/src/paperless/consume
restart: always
volumes:
pgdata:구성 설명
| 컨테이너 | 역할 |
|---|---|
paperless-redis | 작업 큐 관리 (문서 처리 순서 조율) |
paperless-db | 메타데이터 저장 (태그, 날짜, 발신자 등) |
paperless | 메인 앱 (웹 UI, OCR, 문서 처리) |
💡 PAPERLESS_OCR_LANGUAGE: kor+eng 한국어와 영어를 같이 설정해야 국문 문서가 제대로 인식됩니다. 언어팩을 추가하지 않으면 한글이 깨져서 나올 수 있어요.
⚠️ consume 폴더 이 폴더에 파일을 넣으면 자동으로 Paperless가 처리합니다. File Browser와 연동해두면 파일 브라우저에서 드래그해서 넣는 것만으로 자동 처리가 돼요.
💡 실제로 어떻게 활용하면 좋을까요?
영수증 관리 카페나 마트 영수증을 스마트폰으로 찍어서 올리면 됩니다. OCR이 가게 이름, 날짜, 금액을 인식해서 나중에 “스타벅스”로 검색하면 관련 영수증이 다 나와요.
의료 문서 병원 진단서, 처방전, 건강검진 결과서 등을 스캔해두면 의료 기록이 체계적으로 쌓입니다.
금융 문서 카드 명세서, 통장 내역, 보험 증권 등을 PDF로 올려두면 “2024년 국민은행” 이런 식으로 검색이 됩니다.
업무 문서 계약서, 견적서, 세금계산서 등 업무 문서를 체계적으로 보관하고 싶을 때.
✅ 핵심 요약
| 항목 | 내용 |
|---|---|
| 용도 | 문서 디지털 아카이브, 검색 가능한 문서 서재 |
| OCR | Tesseract 엔진, 100개 이상 언어, 완벽하지 않지만 검색엔 충분 |
| 지원 형식 | PDF, 이미지, Office 문서 등 |
| 자동화 | 머신러닝 자동 분류, 이메일 자동 수집 |
| 보안 | 내 서버에서만 처리, 외부 유출 없음 |
| 접속 | Tailscale 전용 |
마치며
Paperless-ngx는 설치하고 바로 효과가 나타나는 프로그램보다는, 문서를 쌓아갈수록 가치가 올라가는 프로그램입니다.
처음엔 몇 장 올려봐도 별거 없어 보이지만, 수십 수백 장이 쌓이고 나서 키워드 하나로 3년 전 영수증을 2초 만에 찾아냈을 때 그 가치를 실감하게 됩니다.
OCR이 완벽하지 않다는 것, 맞습니다. 하지만 “완벽한 인식”이 아니라 “나중에 검색이 되는 것” 이 목표라면 충분히 쓸 만해요. ㅎㅎ
Mark의 한마디: “OCR 인식률이 100%가 아니라는 걸 알고 나면 오히려 마음이 편해집니다. ‘이 단어가 검색에 걸리면 됐다’ 정도로 생각하면 되거든요. 완벽한 텍스트 인식보다, 나중에 찾을 수 있는 것이 중요하니까요 ㅎㅎ”